为什么要优化?
我们大致可以把视频游戏宽泛地分成两类:实时游戏和输入驱动游戏。输入驱动游戏显示游戏当前的状态,在继续工作之前,会无限制地等待,直到有用户输入发 生。棋牌类游戏就属于此类,还有大部分迷题类、策略类以及文字型冒险游戏。实时游戏,有时候称为技巧或动作游戏,并不会等待游戏者,他们会一直工作,直到 Game Over。技巧或动作游戏的特性,通常体现在屏幕上大量地移动(想象一下 Galaga[注]或者 Robotron [注])。 刷新频率必须至少有 10 fps(frame persecond,每秒帧数),并且要有足够的动作来保持游戏有挑战性。这些游戏需要游戏者有快速的反应能力以及良好的眼手协调能力,因此成功的 S&A游戏同样要求对用户的输入有非常好的回馈。提供在高刷新率的图形运算的同时对按键进行快速的响应,正是为什么实时游戏需要高效率编码的原 因。在使用J2ME 进行开发的时候,这更是一项极大的挑战。
Java 2 Micro Edition (J2ME) 是一个被修剪过的 Java版本,适合能力非常有限的小型设备,比如手机和 PDA。J2ME设备有如下特征:
- 受限的输入能力(没有键盘!)
- 显示区域小
- 有限的存储空间和堆
- 较慢的 CPU
用 J2ME平台来开发游戏,对于开发者来讲是一个挑战,因为他们编写的代码需要运行在远远慢于台式机的CPU 之上。
什么时候不优化?
如果你不是在编写一个技巧或者动作游戏,那么可能没有必要进行优化。如果游戏者每几秒钟或几分钟才进行下一步操作,那么他可能并不会介意你的游戏在响应他 的动作时多花了几百毫秒。这条准则的一个例外,是当游戏在决定下一步操作时,需要进行大量的运算,比如在上百万种可能的棋谱中进行搜索,那么你可能需要对 代码进行优化,以确保下一步能在几秒钟内计算出来,而不是几分钟。如果你在编写这类的游戏,优化的过程可谓艰辛。很多这样的技术通常伴随着其它的代价——它们不再是传统意义上的“好”程序,它们使得你的代码不易阅读。我 们需要做出权衡,因为有的时候为了取得那么一点点性能上的改善,却需要我们显著地增大一个程序。J2ME的开发者都太熟悉要尽可能地让 JAR包变小。以下是更多不进行优化的理由:
- 优化很容易引入 bug
- 有些技术会降低代码的移植性
- 你花费了很多努力却只有很小甚至没有结果
- 优化真的很难做
最后一点需要澄清的是,优化是一个变化的目标,在 Java平台上是这样,在 J2ME平台上更是如此,因为运行环境千差万别。你优化过的代码在某个模拟器上可能更快,但是在真实设备上却更慢,反之亦然。在某一种手机上的优化可能实际上降低了在另一种上的性能。
但是希望还是有的。在优化的时候,我们有两种程度,高端的和低端的。前者类似于在所有的平台上提高运行性能,提高代码的整体质量;而后者可能更让你头痛,不过这些低端技术比较容易引入,并且在你不需要他们时也更容易忽略。至少,它们看起来非常有趣。
我们同样用系统时钟来描述在实际设备上的代码,这将帮助你估算在要部署的目标硬件上,这些技术到底多有效率。
最后,重要的一点——
优化充满了乐趣!
一个反面范例
现在让我们来看一个简单的例子,它有两个类,首先是 MIDlet——import javax.microedition.midlet.*;
import javax.microedition.lcdui.*;
public class OptimizeMe extends MIDlet implements CommandListener {
private static final boolean debug = false;
private Display display;
private OCanvas oCanvas;
private Form form;
private StringItem timeItem = new StringItem( "Time: ", "Unknown" );
private StringItem resultItem =
new StringItem( "Result: ", "No results" );
private Command cmdStart = new Command( "Start", Command.SCREEN, 1 );
private Command cmdExit = new Command( "Exit", Command.EXIT, 2 );
public boolean running = true;
public OptimizeMe() {
display = Display.getDisplay(this);
form = new Form( "Optimize" );
form.append( timeItem );
form.append( resultItem );
form.addCommand( cmdStart );
form.addCommand( cmdExit );
form.setCommandListener( this );
oCanvas = new OCanvas( this );
}
public void startApp() throws MIDletStateChangeException {
running = true;
display.setCurrent( form );
}
public void pauseApp() {
running = false;
}
public void exitCanvas(int status) {
debug( "exitCanvas - status = " + status );
switch (status) {
case OCanvas.USER_EXIT:
timeItem.setText( "Aborted" );
resultItem.setText( "Unknown" );
break;
case OCanvas.EXIT_DONE:
timeItem.setText( oCanvas.elapsed+"ms" );
resultItem.setText( String.valueOf( oCanvas.result ) );
break;
}
display.setCurrent( form );
}
public void destroyApp(boolean unconditional)
throws MIDletStateChangeException {
oCanvas = null;
display.setCurrent ( null );
display = null;
}
public void commandAction(Command c, Displayable d) {
if ( c == cmdExit ) {
oCanvas = null;
display.setCurrent ( null );
display = null;
notifyDestroyed();
}
else {
running = true;
display.setCurrent( oCanvas );
oCanvas.start();
}
}
public static final void debug( String s ) {
if (debug) System.out.println( s );
}
}
然后,
OCanvas做了本例中大部分的工作——
import javax.microedition.midlet.*;
import javax.microedition.lcdui.*;
import java.util.Random;
public class OCanvas extends Canvas implements Runnable {
public static final int USER_EXIT = 1;
public static final int EXIT_DONE = 2;
public static final int LOOP_COUNT = 100;
public static final int DRAW_COUNT = 16;
public static final int NUMBER_COUNT = 64;
public static final int DIVISOR_COUNT = 8;
public static final int WAIT_TIME = 50;
public static final int COLOR_BG = 0x00FFFFFF;
public static final int COLOR_FG = 0x00000000;
public long elapsed = 0l;
public int exitStatus;
public int result;
private Thread animationThread;
private OptimizeMe midlet;
private boolean finished;
private long started;
private long frameStarted;
private long frameTime;
private int[] numbers;
private int loopCounter;
private Random random = new Random( System.currentTimeMillis() );
public OCanvas( OptimizeMe _o ) {
midlet = _o;
numbers = new int[ NUMBER_COUNT ];
for ( int i = 0 ; i < numbers.length ; i++ ) {
numbers[i] = i+1;
}
}
public synchronized void start() {
started = frameStarted = System.currentTimeMillis();
loopCounter = result = 0;
finished = false;
exitStatus = EXIT_DONE;
animationThread = new Thread( this );
animationThread.start();
}
public void run() {
Thread currentThread = Thread.currentThread();
try {
while ( animationThread == currentThread && midlet.running
&& !finished ) {
frameTime = System.currentTimeMillis() - frameStarted;
frameStarted = System.currentTimeMillis();
result += work( numbers );
repaint();
synchronized(this) {
wait( WAIT_TIME );
}
loopCounter++;
finished = ( loopCounter > LOOP_COUNT );
}
}
catch ( InterruptedException ie ) {
OptimizeMe.debug( "interrupted" );
}
elapsed = System.currentTimeMillis() - started;
midlet.exitCanvas( exitStatus );
}
public void paint(Graphics g) {
g.setColor( COLOR_BG );
g.fillRect( 0, 0, getWidth(), getHeight() );
g.setColor( COLOR_FG );
g.setFont( Font.getFont( Font.FACE_PROPORTIONAL,
Font.STYLE_BOLD | Font.STYLE_ITALIC, Font.SIZE_SMALL ) );
for ( int i = 0 ; i < DRAW_COUNT ; i ++ ) {
g.drawString( frameTime + " ms per frame",
getRandom( getWidth() ),
getRandom( getHeight() ),
Graphics.TOP | Graphics.HCENTER );
}
}
private int divisor;
private int r;
public synchronized int work( int[] n ) {
r = 0;
for ( int j = 0 ; j < DIVISOR_COUNT ; j++ ) {
for ( int i = 0 ; i < n.length ; i++ ) {
divisor = getDivisor(j);
r += workMore( n, i, divisor );
}
}
return r;
}
private int a;
public synchronized int getDivisor( int n ) {
if ( n == 0 ) return 1;
a = 1;
for ( int i = 0 ; i < n ; i++ ) {
a *= 2;
}
return a;
}
public synchronized int workMore( int[] n, int _i, int _d ) {
return n[_i] * n[_i] / _d + n[_i];
}
public void keyReleased(int keyCode) {
if ( System.currentTimeMillis() - started > 1000l ) {
exitStatus = USER_EXIT;
midlet.running = false;
}
}
private int getRandom( int bound )
{ // return a random, positive integer less than bound
return Math.abs( random.nextInt() % bound );
}
}
本例程序是一个 MIDlet,模拟一个简单的游戏循环:
- 计算
- 画图
- 处理输入
- 反复
对于高速的游戏,这个循环应该尽可能的紧凑。我们的循环进行有限的次数(
LOOP_COUNT =100),并且用一个系统时钟来计算整个过程花费了多少时间(毫秒),这样我们就能测量并且改进其性能。时间和结果显示在一个简单的表单中。用“开始”命令来启动测试,按任意键中止循环,用“退出”命令退出程序。在大多数游戏中,游戏主循环的“计算”部分包含了对游戏世界状态的更新——移动主角,测试和响应碰撞,更改分数等。在这个例子中,我们并没有做任何有意义的操作,而只是简单的运行一个数组,对其中每个数字进行一些数学计算,并给出一个总的计算结果。
run()方法同样计算出每次循环所花的执行时间。每一帧,OCanvas.paint() 方法都将在屏幕上 16个位置的其中随机之一显示这个时间的毫秒数。正常情况下你可能会在这个方法中绘制游戏中的元素,这里我们的代码只是对这个过程提供一个合理的模拟。不管这段代码看起来多么没有意义,它都将给我们提供很大的空间来改善运行性能。
哪些地方需要优化——九一原则
在性能较低的游戏中,90% 的时间被花费在运行 10% 的代码上。这 10%的代码正是我们需要集中所有努力优化的地方。我们用一个描述器(profiler)来找出这10% 的代码。要打开 J2ME Wireless Toolkit 中的 ProfilerUtility,可以在 Edit 菜单中选择 Preference 项,打开 Preference窗口,选择 Monitoring 标签,勾选标有“EnableProfiling”的复选框,然后点击“OK”按钮。没有任何事情发生?没关系——我们需要在模拟器中运行我们的程序,然 后退出,这样Profiler 窗口才会出现。现在就试试看吧!Figure 1. 演示如何打开 Profiler Utility
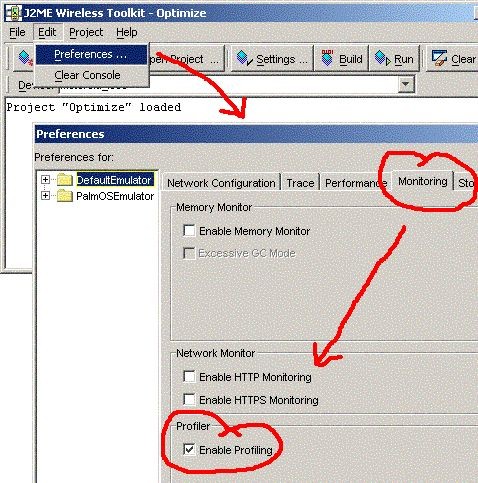
我的模拟器(运行在 Windows XP 下,Intel P4 2.4GHzCPU)报告 100 次循环花费了
6,407ms,即 6 秒半种,每帧61-63ms。在硬件(Motorala i85s)上,它运行慢许多。没帧的时间在500ms
左右,而整个程序跑了52460ms。在这篇文章种,我们将尝试改进这一现象。
当你退出程序时,描述器窗口将弹出来这样你就能看到一个类似于文件夹浏览器的东西,左边面板有一棵树,它分级显示了方法之间的关系。每个文加夹都是一个方 法,打开一个方法的文件夹显示所有该方法调用的其它方法。在树中选择一个方法,将在右边窗口中显示该方法的描述信息以及所有其它被它调用的方法。注意每个 元素附近显示有一个百分数。这个是该方法运行花费的时间占总运行时间的百分比。我们需要浏览这棵树,找出时间到花到哪里去了,然后尽可能地优化那些占有最 高百分比的方法。
Figure 2. Profiler Utility 调用表单
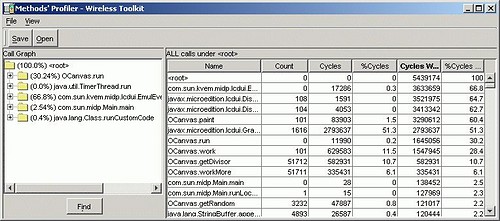
当你退出程序时,描述器窗口将弹出来这样你就能看到一个类似于文件夹浏览器的东西,左边面板有一棵树,它分级显示了方法之间的关系。每个文加夹都是一个方 法,打开一个方法的文件夹显示所有该方法调用的其它方法。在树中选择一个方法,将在右边窗口中显示该方法的描述信息以及所有其它被它调用的方法。注意每个 元素附近显示有一个百分数。这个是该方法运行花费的时间占总运行时间的百分比。我们需要浏览这棵树,找出时间到花到哪里去了,然后尽可能地优化那些占有最 高百分比的方法。
Figure 2. Profiler Utility 调用表单
关于描述器,有些地方需要注意。首先,你所得到的百分比可能和我的会不同,但是方法类似——总是追踪那些最大的数字。我
每次运行程序,这些数字都不同。在做测试时,请尽可能地保持环境统一,你可能需要关掉所有的后台应用程序,比如电子邮件客户端等等。同时,在使用描述器之
前也不要采取任何代码保护措施(如某些让源代码变混乱以防被反编译的工具),否则你的方法会被莫明奇妙的命名为“b”、“a”或者“ff”之类。最后,描
述器本身对性能没有任何帮助,不管你模拟什么设备。硬件本身是完全不同的东西。
打开具有最高百分率的文件夹,我们发现 66.8% 的运行时间被名为
我们例子中这些百分数的分配和真实游戏的情况不会差太远。你会发现,一个真实视频游戏的绝大部分运行时间的大部分都被花费在
Michael Abrash,id software 力作 Quake开发者之一,曾经写到,“最好的优化工具,在你的双耳之间”。一个问题总有不止一个解决办法,如果在行动之前花些时间来考虑正确的方法,则可以 达到事半功倍的的效果。使用正确的(比如最快的)规则体系,对性能的帮助将远远大于用低端技术来改进二流的设计带来的效果。用低端技术你可能可以降低几个 百分点,但是之前请从高端优化开始,多用你的脑子——它就在你的双耳之间。
那么,让我们来看看我们在
当我们运行这个版本的程序时,我们会发现在
你可能会注意到将字符串绘制到图像会影响显示,因为 J2ME并不支持图像的透明处理,因此很多背景被覆盖。对于前面所提到的,优化会导致你对应用的需求重新进行评估,这便是一个很好的例子。如果你真的需要文字的重叠,那么你可能就不得不去处理较慢的运行速度。
这端代码可能会稍好一些,但是仍然有很多优化的空间。接下来我们一起看看我们的第一个低端优化技术。
打开具有最高百分率的文件夹,我们发现 66.8% 的运行时间被名为
com.sun.kvem.midp.lcdui.EmulEventHandler$EventLoop.run的方法消耗,这对我们帮助不大。继续向下挖掘一两层具有类似奇怪名称的方法文件夹,你将追踪到大的百分比方法serviceRepaints(),然后最终到我们的OCanvas.paint() 方法。另外30%的时间被它消耗。这两个方法都存在于游戏的主循环终,这并不奇怪——我们不会花费时间去优化MIDlet类中的代码,同时你也不会去为优化游戏主循环之外的代码费心。只优化那些反复运行的部分。我们例子中这些百分数的分配和真实游戏的情况不会差太远。你会发现,一个真实视频游戏的绝大部分运行时间的大部分都被花费在
paint()方法上。和非图像处理的部分比起来,图像处理的常规操作会花费非常多的时间。遗憾的是,图像处理的常规操作早已封装在J2ME API之下,在这一点上,我们没有多少余地用来改善其性能。我们所能做的是,聪明地决定我们用它们中的哪一个,以及如何使用它们。高端优化 VS. 低端优化
本文后面将讨论有关低端优化技术。你将发现它们很容易应用到已存在的代码中,虽然会降低代码的可读性,但是会带来性能的提升。在你使用这些技术之前,最好先改善你代码的设计以及规则(algorithms),也就是高端优化。Michael Abrash,id software 力作 Quake开发者之一,曾经写到,“最好的优化工具,在你的双耳之间”。一个问题总有不止一个解决办法,如果在行动之前花些时间来考虑正确的方法,则可以 达到事半功倍的的效果。使用正确的(比如最快的)规则体系,对性能的帮助将远远大于用低端技术来改进二流的设计带来的效果。用低端技术你可能可以降低几个 百分点,但是之前请从高端优化开始,多用你的脑子——它就在你的双耳之间。
那么,让我们来看看我们在
paint()方法里面干了些什么。每次循环我们调用了 16 次 Graphics.drawString()方法用来在屏幕上显示“n ms per frame”。我们并不知道drawString方法内部的工作原理,但是我们知道它被用了很多次,于是让我们尝试一下另一种途径。我们可以把字符串直接一次性画到一个Image 对象中,然后将该Image 绘制 16 次。
public void paint(Graphics g) {
g.setColor( COLOR_BG );
g.fillRect( 0, 0, getWidth(), getHeight() );
Font font = Font.getFont( Font.FACE_PROPORTIONAL,
Font.STYLE_BOLD | Font.STYLE_ITALIC,
Font.SIZE_SMALL );
String msMessage = frameTime + "ms per frame";
Image stringImage =
Image.createImage( font.stringWidth( msMessage ),
font.getBaselinePosition() );
Graphics imageGraphics = stringImage.getGraphics();
imageGraphics.setColor( COLOR_BG );
imageGraphics.fillRect( 0, 0, stringImage.getWidth(),
stringImage.getHeight() );
imageGraphics.setColor( COLOR_FG );
imageGraphics.setFont( font );
imageGraphics.drawString( msMessage, 0, 0,
Graphics.TOP | Graphics.LEFT );
for ( int i = 0 ; i < DRAW_COUNT ; i ++ ) {
g.drawImage( stringImage, getRandom( getWidth() ),
getRandom( getHeight() ),
Graphics.VCENTER | Graphics.HCENTER );
}
}
当我们运行这个版本的程序时,我们会发现在
paint()方法上花费的时间的百分率变小了一点点。更深入的观察我们会发现drawString 方法仅被调用了101 次,而 drawImage()方法做了大部分的动作,被调用了 1616次。尽管如此我们还是有成效,程序跑得更快了,因为我们使用的图形调用更快。你可能会注意到将字符串绘制到图像会影响显示,因为 J2ME并不支持图像的透明处理,因此很多背景被覆盖。对于前面所提到的,优化会导致你对应用的需求重新进行评估,这便是一个很好的例子。如果你真的需要文字的重叠,那么你可能就不得不去处理较慢的运行速度。
这端代码可能会稍好一些,但是仍然有很多优化的空间。接下来我们一起看看我们的第一个低端优化技术。
循环之外?
在for()循环内的代码,循环多少次,它们就被执行多少次。因此,为了改进性能,我们需要尽可能的把代码放在循环之外。我们在描述器中会发现我们的paint() 方法被调用了 101次,并且循环执行了 16次。我们可以把哪些东西放在循环之外呢?让我们从所有的声明(declaration)开始。每次调用paint()方法,我们都声明了一个 Font,一个 String,一个 Image 以及一个 Graphics对象。我们可以将这些从该方法中挪出来,放到类的顶部。
public static final Font font =
Font.getFont( Font.FACE_PROPORTIONAL,
Font.STYLE_BOLD Font.STYLE_ITALIC,
Font.SIZE_SMALL);
public static final int graphicAnchor =
Graphics.VCENTER Graphics.HCENTER;
public static final int textAnchor =
Graphics.TOP Graphics.LEFT;
private static final String MESSAGE = " ms per frame";
private String msMessage = "000" + MESSAGE;
private Image stringImage;
private Graphics imageGraphics;
private long oldFrameTime;
你会发现我把
Font对象设置成为共有的常量。这在程序中通常很有用,比如这里你可以把常用到的字体在同一个地方集中定义。我发现锚(anchor)也是一样,因此对文字以及图形的锚也做了同样的处理。预先计算这些东西,保证了计算的结果,虽然微不足道,但是我们将它们从循环中挪了出来。我同样把
MESSAGE也设置成了常量。这是因为 Java 总是喜欢到处创建 String对象。如果不控制好,这些字符串将消耗大量的内存。别不以为然,当你过多的消耗内存,将转而影响整体性能,尤其当垃圾收集器被频繁调用的时候。字符串制造垃圾,而垃圾是糟糕的;而使用字符串常量能缓解这个问题。稍后我们会讲到如何利用StringBuffer来完全解决由字符串泛滥带来的内存损耗。现在我们将这些东西变成了实例变量(instancevariables),我们需要在构造方法上添加如下代码:
stringImage = Image.createImage( font.stringWidth( msMessage ),
font.getBaselinePosition() );
imageGraphics = stringImage.getGraphics();
imageGraphics.setFont( font );
把
Graphics对象提出来,另一点很爽的地方在于,我们只需要对字体设置一次,然后就可以完全不再去管它;而不用每次循环的时候都来设置它。不过仍然每次都需要调用fillRect()方法来擦去图像上的内容。编码狂人们可能会想要这样做,从同一个Image 创建两个Graphics对象,然后将其中一个的颜色预设为 COLOR_BG 用来调用 fillRect(),另一个设置为 COLOR_FG 用来调用 drawString()。很遗憾,J2ME 中,对同一个Image 多次调用getGraphics()方法的行为,定义的并不好,不同的平台会有不同的结果,因此你优化的结果可能对Motorola 有效但 NOKIA却不行。当无法确定的时候,不要做任何无根据假设。还有另一个改进
paint()方法的途径。动动我们的脑子我们会意识到,仅当 frameTime的值发生改变的时候我们才需要重绘该字符串。这也就是我们引入新的变量oldFrameTime的原因。以下是新的方法:
public void paint(Graphics g) {
g.setColor( COLOR_BG );
g.fillRect( 0, 0, getWidth(), getHeight() );
if ( frameTime != oldFrameTime ) {
msMessage = frameTime + MESSAGE;
imageGraphics.setColor( COLOR_BG );
imageGraphics.fillRect( 0, 0, stringImage.getWidth(),
stringImage.getHeight() );
imageGraphics.setColor( COLOR_FG );
imageGraphics.drawString( msMessage, 0, 0, textAnchor );
}
for ( int i = 0 ; i < DRAW_COUNT ; i ++ ) {
g.drawImage( stringImage, getRandom( getWidth() ),
getRandom( getHeight() ), graphicAnchor );
}
oldFrameTime = frameTime;
}
描述器现在显示
OCanvas 的paint()方法所花费的时间占总时间的百分率已经下降到了 41.02%。相比以前由drawString() 和fillRect() 引发的 101 次paint() 来讲,现在只调用了69次。这是相当不错的改进,而且可以继续的空间不多了,这也是我们该认真起来的时候。优化总是越来越难。现在我们要刮掉循环中最后一点冗余的代码。我们可能只能再削减非常少的百分率,但是如果幸运的话,还是可以得到一些显著的改进。让我们先从简单的开始。相比起调用
getHeight() 和 getWidth()方法,我们可以只调用它们一次,然后把结果缓存在循环之外。然后我们要停止使用String,而用StringBuffer来手动地处理。我们可以通过调用 Graphics.setClip() 限制绘制区域来减少drawImage()调用所花费地时间。最后,我们要避免在循环中调用 java.util.Random.nextInt()。以下是新的变量……
private static final String MESSAGE = "ms per frame:";
private int iw, ih, dw, dh;
private StringBuffer stringBuffer;
private int messageLength;
private int stringLength;
private char[] stringChars;
private static final int RANDOMCOUNT = 256;
private int[] randomNumbersX = new int[RANDOMCOUNT];
private int[] randomNumbersY = new int[RANDOMCOUNT];
private int ri;
以下是新的构造方法……
iw = stringImage.getWidth();
ih = stringImage.getHeight();
dw = getWidth();
dh = getHeight();
for ( int i = 0 ; i < RANDOMCOUNT ; i++ ) {
randomNumbersX[i] = getRandom( dw );
randomNumbersY[i] = getRandom( dh );
}
ri = 0;
stringBuffer = new StringBuffer( MESSAGE+"000" );
messageLength = MESSAGE.length();
stringLength = stringBuffer.length();
stringChars = new char[stringLength];
stringBuffer.getChars( 0, stringLength, stringChars, 0 );
你会发现我们预先计算了
Display 和图像的区域,还缓存了对getRandom() 方法的 512次调用,并用 StringBuffer取代了 msMessage字符串。当然,最大的目标还是 paint() 方法:
public void paint(Graphics g) {
g.setColor( COLOR_BG );
g.fillRect( 0, 0, dw, dh );
if ( frameTime != oldFrameTime ) {
stringBuffer.delete( messageLength, stringLength );
stringBuffer.append( (int)frameTime );
stringLength = stringBuffer.length();
stringBuffer.getChars( messageLength,
stringLength,
stringChars,
messageLength );
iw = font.charsWidth( stringChars, 0, stringLength );
imageGraphics.setColor( COLOR_BG );
imageGraphics.fillRect( 0, 0, iw, ih );
imageGraphics.setColor( COLOR_FG );
imageGraphics.drawChars( stringChars, 0,
stringLength, 0, 0, textAnchor );
}
for ( int i = 0 ; i < DRAW_COUNT ; i ++ ) {
g.setClip( randomNumbersX[ri], randomNumbersY[ri], iw, ih );
g.drawImage( stringImage, randomNumbersX[ri],
randomNumbersY[ri], textAnchor );
ri = (ri+1) % RANDOMCOUNT;
}
oldFrameTime = frameTime;
}
我们现在用
StringBuffer来绘制消息的字符。在 StringBuffer结尾添加字符,比在开头插入要容易,因此我们调整了显示文字,frameTime放到了消息的结尾,即“ms per frame:120”。这样我们每次只是更改frameTime的几个字符,而消息的文字则原封不动。像这样使用 StringBuffer,能够让系统不至于在每次循环的时候都要创建和销毁String对象。这是额外的工作,但是值得。注意我把 frame 强转成了 int,因为我发现使用 append(long)会导致内存泄漏。我不知道为什么,不过这是很好的一个例子说明为什么在使用工具的时候要用眼睛盯好。我们还用了
font.charsWidth()来计算消息图像的宽度,这样我们能够尽量少做绘制的工作。我们使用了一个等宽的字体,因此图像“msper frame:1”会比“ms per frame:888”小,而我们又在使用Graphics.setClip(),因此我们不需要绘制多余的部分。这也意味着我们需要绘制一个足够大的矩形来清空我们需要的区域。当然,我们希望在绘图上节省的时间比因调用font.charsWidth()而多花的时间要多。可能这里并不会有太大的意义,但是对于在游戏中在屏幕上绘制玩家的分数来讲,这是一项非常重要的技术。在这个情况下,绘制分数0 和 150,000,000 是很不一样的。这里受到了
font.getBaselinePosition()实现的错误返回值的阻碍,因为本来应该返回和 font.getHeight() 相同的值。唉~!最后我们来看一下用两个数组存放的预计算的“随机”坐标,使得我们不用在循环中进行随机调用。注意这里用了一个取模操作来实现闭合的数组。同时注意我们现在使用
textAnchor来绘制图像和字符串,这样 setClip() 才能正确工作。根据这个版本的代码所产生的数字,我们目前处于一个比较尴尬的境地。描述器告诉我,现在
paint()方法比没有做这些改变时,多花大约 7% 的时间。这可能得怪对font.charsWidth()的调用,因为它占用了4.6%。(这并不太多,但是应该可以被减少。注意我们每次都在取得MESSAGE字符串的宽度,实际上我们可以在循环体之前就轻易的计算出,然后再加上frameTime的宽度。)同时,对 setClip() 的调用标示的是 0.85%,而花在drawImage上的时间看起来增加的比较显著(从 27.58% 到 33.94%)。基于这一点,看起来当然是这些增加的代码把我们的程序变慢了,但是程序生成的值却和这个假设相矛盾。模拟器上的图表很不稳定,因此如果没有更多的测试我们无法得到确定的结论。然而,我的i85s 却报告说,加上这些代码后,程序变快了一点点。只调用
setClip() 或者charsWidth(),
结果为37130ms,而两个都调用得话,结果是36540。在我耐心能够坚持的情况下,我把这个测试运行了很多遍,而结果是相同的。这也再次强调了不同
的运行环境会有不同的结果。当你到了某一点无法确定是否做了改进的时候,你可能被迫在硬件上继续所有的测试,这需要对JAR
文件进行很多安装和卸载工作。那么看起来我们从常规的图形操作上挤出了不少的性能。现在是时候对我们的
work()方法实施高端和低端优化的时候了。先让我们来复习一下这个方法:
public synchronized int work( int[] n ) {
r = 0;
for ( int j = 0 ; j < DIVISOR_COUNT ; j++ ) {
for ( int i = 0 ; i < n.length ; i++ ) {
divisor = getDivisor(j);
r += workMore( n, i, divisor );
}
}
return r;
}
每次进入循环的时候,我们都会传入我们的数组。
work()方法中外层的循环计算我们的除数(divisor),然后调用 workMore()来实施除法。可能已经发现,这里整件事情都有问题。开始的时候,编程的把对getDivisor()的调用放到了内层循环。由于 j的值在内层循环过程中并不发生改变,因此除数也不发生变化,这完全应该放在内层循环之外。如果我们再多考虑一点。这个调用本身也是完全没有必要的。以下代码可以做同样的事情……
public synchronized int work( int[] n ) {
r = 0;
divisor = 1;
for ( int j = 0 ; j < DIVISOR_COUNT ; j++ ) {
for ( int i = 0 ; i < n.length ; i++ ) {
r += workMore( n, i, divisor );
}
divisor *= 2;
}
return r;
}
现在我们的描述器报告说我们的
run() 方法花费 23.72%的时间,而我们做这些改进之前,这个值为38.78%。在陷入低端优化把戏之前,请总是先用头脑来优化。不过,说到这里,还是让我们来看看这些小把戏。