转自: http://www.ismyway.com
由于本人在做 MOTO 手机上的一款阅读器 Anyview 时,并不满意手机自带的字库,因此,使用了外挂字库,在编码过程中,总结了一些经验,特记录下来与大家分享。虽然阅读器是使用 J2ME 开发,但其基本原理实现并未使用特别的 J2ME 的 API 。
前言:为什么要使用点阵字库
在某些场合,系统自带的字库并不能令人满意,或者,在你需要特别的字体时,你希望能附带上该字库。
那为什么又需要点阵字库呢?因为在使用较小的字体的时候,点阵字库能更清晰,同时,由于点阵字库并不包含路径等信息,因此,字库文件的大小也很小,便于携带。
如何生成点阵字库
在 此,我并没有打算在此文中说明如何生成点阵字库,其实有很多现成的点阵字库可以选择,当然,目前都是使用 TrueType 字库,但很多比较老的程序都会带有点阵字库,你可以直接拿来使用,或者,网上也有很多生成点阵字库的工具,当然,你甚至可以自己写一个小程序来生成点阵字 库。
我们这里将直接使用 UCODS 自带的字库来举例子,你也可以使用《特大点阵字库制作软件》来生成一个点阵字库。
点阵字库的组成
点阵字库的组成基本上都类似,除了有些点阵字库可能会在文件头上附加一些版权信息外,基本上没有其它变化,另外,他们在点阵信息的压缩上都会采用相同的方式。下面我们举个例子看看:

上图是一个 12*12 大小的“我”字,从栅格中可以看到,每个点的位置上只会有“有”和“无”两种状态,由左至右。因此,上面的点阵信息可以如下描述:
|
第 1 行 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
|
第 2 行 |
1 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
|
第 3 行 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
第 4 行 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
|
第 5 行 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
第 6 行 |
…… | |||||||||||
由于每个点的信息只有 0 和 1 两种状态,因此,为了节省存储空间,我们使用位的存储点的信息。我们知道,一个字节有 8 位,因此,上面的一个点阵字,可以用若干个字节来进行描述。
当然,不同的点阵大小,每一行的点不一样多,并不能保证他们总是 8 的倍数,因此,最后不足 8 个字节的仍然占用一个字节,且从最高位向最低位排列,不足的地方补 0 。
1 : 00001010 1000 →补位→ 00001010 10000000 → Ox0a 0x80
2 : 11110010 0100 →补位→ 11110010 01000000 → 0xf2 0x40
3 : 00010010 0000 →补位→ 00010010 00000000 → 0x12 0x00
4 : 11111111 1110 →补位→ 11111111 11100000 → 0xff 0xe0
5 : 00010010 0000 →补位→ 00010010 00000000 → 0x12 0x00
……
由上可知,对于一个 12*12 的汉字来说,一个字需要占用 2 × 12 = 24 个字节。我们已经知道了每一个字的存储方式,那么,在字库中,这些字是按照什么顺序来存储的呢?
我 们知道,不同的语言使用不同的字符集,对于汉字来说,有很多种字符集如 GB2312 、 BIG5 、 GBK 等,当然,还有更大的字符集如 UTF-8 、 UNICODE 等,在我们的程序中,我们必须确定一种字符集,为了简单起见,我们以 GB2312 举例子。(关于各字符集的说明,自己可以在网上搜索一下)
GB2312 规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。 GB2312-80 包含了大部分常用的一、二级汉字,和 9 区的符号。该字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,这也是最基本的中文字符集。其编码范围是高位 0xa1 - 0xfe ,低位也是 0xa1-0xfe ;汉字从 0xb0a1 开始,结束于 0xf7fe 。
GB2312 将代码表分为 94 个区,对应第一字节( 0xa1-0xfe );每个区 94 个位( 0xa1-0xfe ),对应第二字节,两个字节的值分别为区号值和位号值加 32 ( 2OH ),因此也称为区位码。 01-09 区为符号、数字区, 16-87 区为汉字区( 0xb0-0xf7 ), 10-15 区、 88-94 区是有待进一步标准化的空白区。 GB2312 将收录的汉字分成两级:第一级是常用汉字计 3755 个,置于 16-55 区,按汉语拼音字母 / 笔形顺序排列;第二级汉字是次常用汉字计 3008 个,置于 56-87 区,按部首 / 笔画顺序排列。故而 GB2312 最多能表示 6763 个汉字。
仍然是 12*12 点阵的“我”字为例,“我”的编码为 0xCED2 ,因此,在字库文件中,“我”字的偏移为: ((0xCE-0xA1)*94+(0xD2-0xA1))*24 字节 / 字 =102696 ,其后的连续 24 字节即为“我”字的点阵信息。
| public class CharCode { public CharCode() { String str = "我"; try { byte[] b = str.getBytes("GB2312"); for (int i = 0; i < b.length; i++) { System.out.println(Integer.toHexString(b[i])); } } catch (Exception ex) { } } public static void main(String[] args) { |
将点阵信息还原为汉字
由于我们已经能够顺利的找到汉字的点阵数据,因此,我们只需要简单的将点阵信息还原即可。还原的方法很简单,只需要按照上述格式逆向操作就行了:
“我”字的信息第一个字节为 Ox0a ,从高位向低位依次取当前位上的数据,如果为 1 ,表示该点需要着色, 0 则表示该点为空,为了取位的方便,我们可以直接定义一个数组来与该字节异或:
| public final static int[] verify = {128, 64, 32, 16, 8, 4, 2, 1}; 然后,作如下判断: for (int w = 0; w < 8; w++) { if ((b & verify[w]) == verify[w]) { //需要着色 //着色 } } |
下面,我们以一段小的程序来完成该工作:
| import java.io.*; import javax.swing.*; import java.awt.*; import java.awt.image.*; public class Test extends JFrame { public Test() { File file = new File("gb.dat"); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); void createCH(byte[] ch, int off) { public void paint(Graphics g) { byte[] str2bytes(String s) { public static void main(String[] args) { |
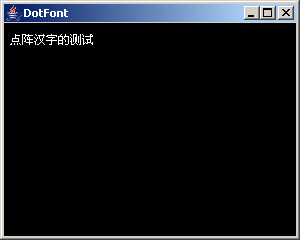
在 上述代码中, gb.dat 是直接从 UCDOS 中自带的 12 点阵字库,当然,你也可以使用其它工具生成,为了提高效率,我们直接将整个字库加载到内存中。 str2bytes(String s)是用来将字符串转换成为 GB2312 编码格式的二进制字节数组,在 createCH(byte[] ch, int off) 中,我们创建了一个空白的图片,然后根据字库的点阵信息,来决定是否使用 setRGB()方法为该点着色,最后,将创建的图片画在程序的画布上。
(当然,以上程序仅仅是演示,并没有考虑效率的问题和对英文字库的处理)
编译并运行该程序,你会得出如下的界面:
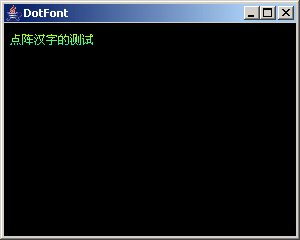
至此,我们的点阵字库显示程序已经可以正常工作了,在这里,其实我们还可以玩一点小小的技巧,定义一个颜色数组
int[] color = {0xbbff00, 0xaaff11, 0x99ff22, 0x88ff33, 0x77ff44, 0x66ff55, 0x55ff66, 0x44ff77, 0x33ff88, 0x22ff99, 0x11ffaa, 0x00ffbb};
然后,在使用 setRGB()时根据当前行的位置来使用数组中相对索引的颜色:
将
imgCH.setRGB(w + 8, h, 0xffffffff);
改为
imgCH.setRGB(w + 8, h, color[h]);
这个小小的修改并不会降低代码的执行效率,并且,你将会得到如下图的效果: